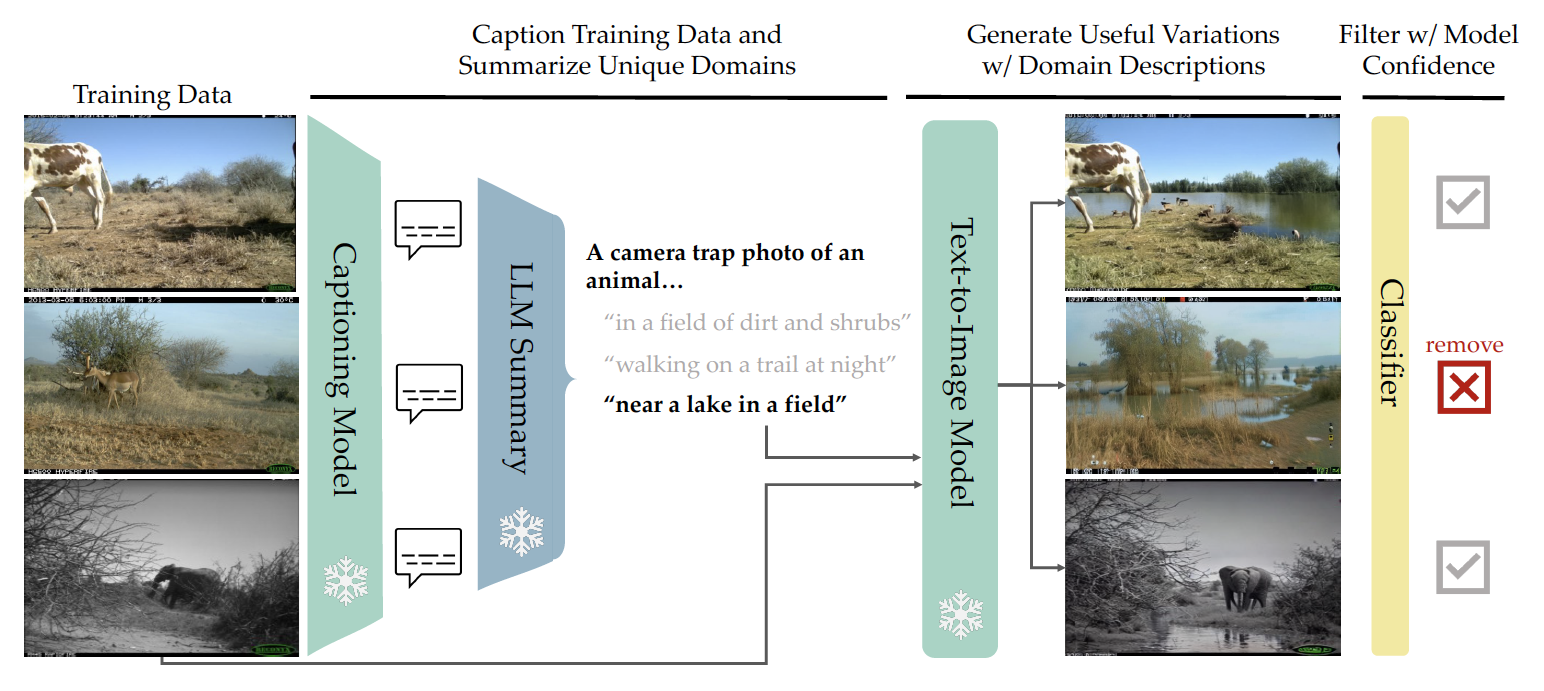
Takeaway 1: use captioning models and LLM's to extract task-agnostic concepts from training data, then edit training images using these text concepts to diversify your training set.
Takeaway 2: Image-editing is preferred over pure generation if your task is specialized.
Abstract
Many fine-grained classification tasks, like rare animal identification, have limited training data and consequently classifiers trained on these datasets often fail to generalize to variations in the domain like changes in weather or location. As such, we explore how natural language descriptions of the domains seen in training data can be used with large vision models trained on diverse pretraining datasets to generate useful variations of the training data. We introduce ALIA (Automated Language-guided Image Augmentation), a method which utilizes large vision and language models to automatically generate natural language descriptions of a dataset's domains and augment the training data via language-guided image editing. To maintain data integrity, a model trained on the original dataset filters out minimal image edits and those which corrupt class-relevant information. The resulting dataset is visually consistent with the original training data and offers significantly enhanced diversity. On fine-grained and cluttered datasets for classification and detection, ALIA surpasses traditional data augmentation and text-to-image generated data by up to 15%, often even outperforming equivalent additions of real data.